
CPU/GPU联合编程
CPU/GPU联合编程
由示例代码可以知道,只要调用了 cuda 函数把模型移动到 GPU 之上,我们就可以使用 CUDA global 核函数在GPU上进行并行运算。
1 | model = ToyModel().cuda(device_ids[0]) # 这里复制模型到 GPU 之上 |
但是我们忽略了一个问题,就是 PyTorch 怎么知道此时应该调用GPU对应的 global 核函数?为什么 PyTorch 就不调用 CPU 函数或者其他设备的函数了?这就是我们接下来需要分析的。
Dispatcher 机制
在PyTorch中,operator 所表现出预期行为是由很多机制共同作用导致的,比如:
- 做实际工作的kernel。
- 是否支持反向自动微分,例如,使 loss.backward() 正常工作的标记位。
- 是否启用了torch.jit.trace。
- 如果你正在vmap调用中,所运行operator将会表现出不同的批处理行为
对Pytorch operator而言,它需要对一个单一函数,如add,里面的所有行为都安排好在哪做怎么做,这样实现代码就会变成了一个非常混乱而且不可维护的局面,所以需要有一个机制来解决这个问题,而且这个机制应该是一个抽象,而不是简单的if语句。最后它必须在尽可能不降低PyTorch性能的情况下做到这一点。这个机制就是 Dispatcher。
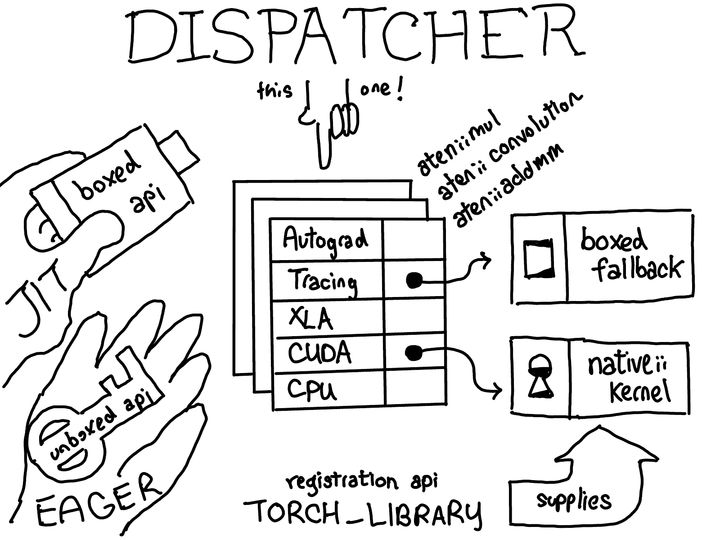
什么是 Dispatcher
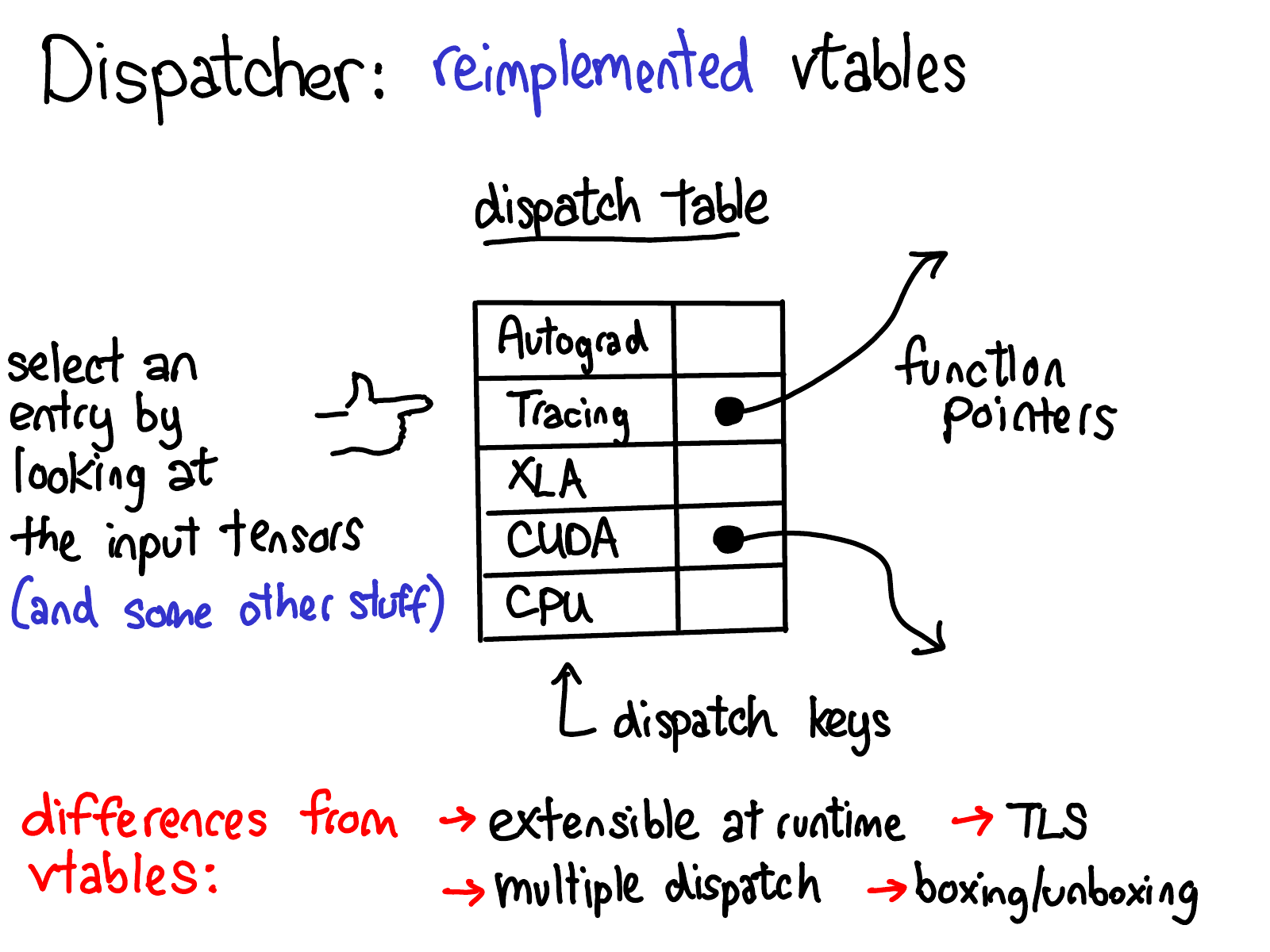
dispatcher对于每个operator都会维护一个函数指针表,这些函数为每个dispatch key提供了对应的实现,这套机制大致对应于PyTorch中的一个横切关注点。在上图中,你可以看到在这个表中有针对不同后端(CPU、CUDA、XLA)以及更高级概念(例如 autograd 和跟踪)的dispatch条目。dispatcher的工作是根据输入的tensor和其他一些东西(比如参数个数,返回值类型等等)来计算出一个dispatch key,然后跳转到函数指针表所指向的函数。
熟悉 C++ 的人可能会注意到,这个函数指针表与C++中的虚表非常相似。在C++中,对象的虚函数是通过将每个对象与一个虚表的指针相关联来实现的,该虚表包含了有关对象上每个虚函数的实现。在PyTorch中,我们基本上重新实现了虚拟表,但有一些区别。
- dispatch表之中包括了 dispatch key 和其对应的函数指针,我们可以发现,dispatch key不仅仅有后端(CPU、CUDA、XLA),也有一些更高级的概念(例如 autograd 和跟踪)。
- dispatch表是按operator分配的,而虚表是按类分配的。这意味着我们可以通过分配一个新的dispatch表来扩展所支持的operator集。与其不同的是,对于一个C++对象,你可以通过继承子类来扩展类型,但你不能轻易添加虚函数。与普通的面向对象系统不同,PyTorch大部分的可扩展性在于定义新的operator(而不是新的子类),所以这种权衡是合理的。此外,dispatch key的种类不是公开可扩展的,PyTorch核心团队希望那些想添加新dispatch key的使用者通过向PyTorch核心团队提交一个补丁来添加他们的dispatch key。
- PyTorch的dispatch key的计算考虑了operator的所有参数(multiple dispatch)以及线程本地状态(TLS)。这与虚表不同,在虚表中只有第一个对象(this指针)很重要。
- 最后,dispatcher支持boxing和unboxing作为op的调用约定的一部分。在文章的最后部分会有更多关于这个的内容。
有趣的历史笔记:PyTorch曾经使用虚函数来实现动态dispatch,当我们意识到需要比虚表更多的能力时,我们重新实现了动态dispatch。
如何计算key
那么,PyTorch究竟是如何计算dispatch key的呢?PyTorch是基于dispatch key set来完成的,dispatch key set是一个基本抽象,它是dispatch key的一个bitset。大致来讲,PyTorch综合来自不同来源的dispatch key sets(在某些情况下屏蔽一些key)来得到一个最终的dispatch key set。然后我们在这个set中挑选优先级最高的key(dispatch keys按某些优先级隐式排序),这就是PyTorch这次应该调用的结果。那么,这些dispatch key sets的来源是什么?
- 每个张量输入都有一个由该张量上的所有dispatch key组成的dispatch key set(直观地说,这些dispatch key的值会是类似 “CPU”字符串这样的东西,这告诉我们该张量是一个CPU张量,所以应该由dispatch表中的CPU handler来处理)。
- PyTorch还有一个local include set,用于 “模态(modal) “功能,例如tracing,它不与任何张量关联,而是某种线程的本地模态,用户可以在某些范围内打开或关闭。
- 最后,PyTorch有一个global set,它包含了始终应该被考虑的dispatch key(自从写下这张PPT以来,Autograd已经从global set转移到了张量之上。然而系统的高级结构并没有改变)。
除了这些,还有一个local exclude set,其用从dispatch排除某些dispatch key。一个常见的场景是一个handler负责处理一个key,然后通过local exclude set将自己屏蔽掉,这样PyTorch以后就不会尝试重新处理这个key。

注册
我们接下来看看如何注册这个dispatch key 到 dispatch 表之中。这个过程通过operator registration API来实现。操作符注册 API 有三种主要方式:
- 为operator定义模式。
- 然后在对应的key上注册实现。
- 最后,有一个 fallback 方法,用户可以使用它为某个key对应的所有运算符定义同一个处理程序。

为了可视化 operator registration的工作,让我们想象一下,所有op的dispatch表共同形成一个二维网格,像这样:
- 纵轴上是PyTorch中支持的每个op。
- 横轴上是系统支持的每个dispatch key。
operator registration 行为就是在这两个轴定义出的单元格中填写对应的实现。

在一个特定的dispatch key上为一个operator注册kernel函数时,我们会填写一个单元格(下面的蓝色)的内容。比如下图就是一个 cpu kernel mul 算子。

用户也可以使用 “catch-all” 来为所有的 dispatch keys 注册同一个kernel,比如下图的红色行。

用户也可以为下图的 “aten::add”,”aten::mul”,”aten::sub” 这样的kernel 指定同一个 dispatch key,如下图绿色列。

这些注册形式有一个优先级:特定的内核实现具有最高优先级,然后是 catch,最后是 fallback,如下图的 1,2,3 顺序,首先选择1,然后是 2,最后是 3。


