Lecture 2 A Modern Multi-Core Processor
- 理解并行计算的形式
- 理解延迟(latency)和带宽(bandwidth)
Parallel Execution
单线程执行 - 编译器定义
例程:使用泰勒公式计算$sin(x)$。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| void sinx(int N,int terms, float* x,float* result){
for(int i=0;i<N;i++){
float value = x[i];
float numer = x[i] * x[i] *x[i];
int denom = 6;
int sign = -1;
for(int j=1;j<= terms;j++){
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2)*(2*j+3);
sign *= -1;
}
result[i]=value;
}
}
|
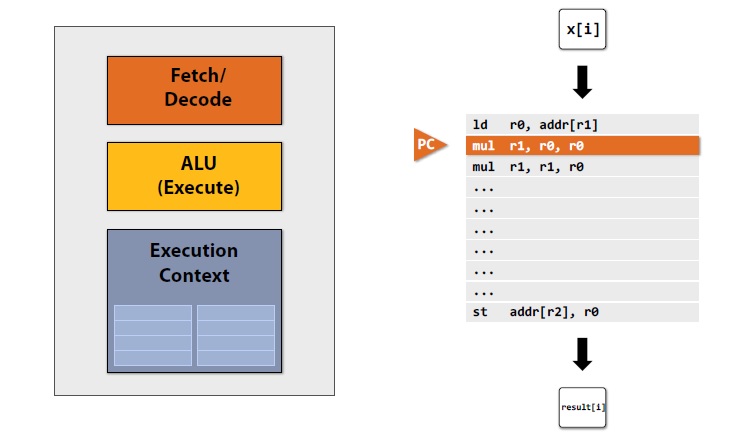
- 解码模块(Fetch/Decode)读取指令
- ALU模块负责执行
- 上下文存储器(Exceution Context)负责存储执行数据
多线程执行 - 用户定义
概念:指令级并行 instruction level parallelism (ILP)
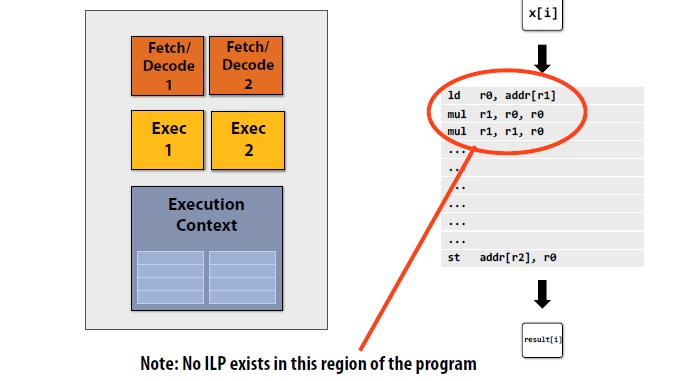
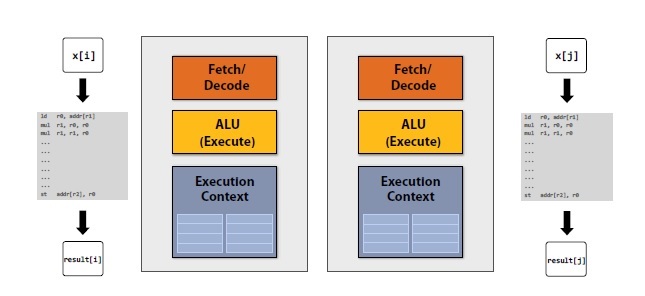
例程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| typedef struct{
int N;
int terms;
float *x;
float result;
} my_args;
void parallel_sinx(int N,int terms, float* x,float* result){
pthread_t thread_id;
my_args args;
args.N=2/N;
args.terms=terms;
args.x=x;
args.result=result;
pthread_create(&thread_id, NULL, my_thread_start, &args);
sinx(N-args.N,terms,x+args.N,result+args.N);
pthread_join(thread_id, NULL);
}
void sinx(int N,int terms, float* x,float* result){
for(int i=0;i<N;i++){
float value = x[i];
float numer = x[i] * x[i] *x[i];
int denom = 6;
int sign = -1;
for(int j=1;j<= terms;j++){
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2)*(2*j+3);
sign *= -1;
}
result[i]=value;
}
}
|
上述例程表示线程级并行的代码描述,通过将整个工作分散分配到不同的处理器核中,以获得加速的效果。工作的分配方式将很大程度上影响加速的效果。
数据并行 - 用户定义、编译器定义
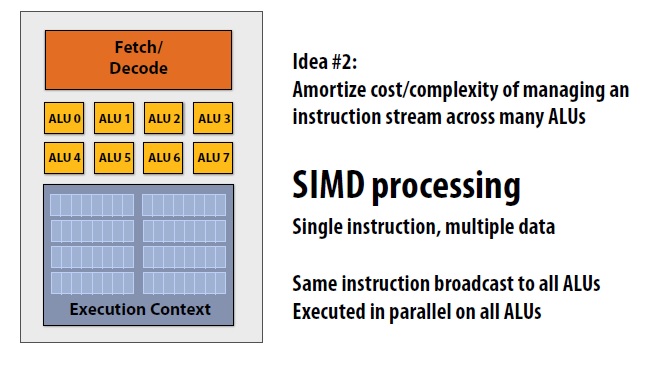
概念:SMID 单指令多数据处理
使用AVX指令集的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #include <immintrin.h>
void sinx(int N, int terms, float* x, float* sinx)
{
float three_fact = 6;
for (int i=0; i<N; i+=8)
{
__m256 origx = _mm256_load_ps(&x[i]);
__m256 value = origx;
__m256 numer = _mm256_mul_ps(origx, _mm256_mul_ps(origx, origx));
__m256 denom = _mm256_broadcast_ss(&three_fact);
int sign = -1;
for (int j=1; j<=terms; j++)
{
__m256 tmp = _mm256_div_ps(_mm256_mul_ps(_mm256_broadcast_ss(sign),numer),denom);
value = _mm256_add_ps(value, tmp);
numer = _mm256_mul_ps(numer, _mm256_mul_ps(origx, origx));
denom = _mm256_mul_ps(denom, _mm256_broadcast_ss((2*j+2) * (2*j+3)));
sign *= -1;
}
_mm256_store_ps(&sinx[i], value);
}
}
|
按照上图所示CPU模型,通过使用SMID单个核可以一次指令同时处理8个数据,达到并行处理数据的效果。
另一种自动优化代码的写法,前提是循环loop之间相互独立
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void sinx(int N, int terms, float* x, float* result)
{
forall (int i from 0 to N-1)
{
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6;
int sign = -1;
for (int j=1; j<=terms; j++)
{
value += sign * numer / denom
numer *= x[i] * x[i];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[i] = value;
}
}
|
条件执行
假设数据并行处理器需要执行如下代码
1
2
3
4
5
6
7
8
9
| float x = A[i];
if(x>0){
float tmp = exp(x,5.f);
x = tmp + kMyConst2;
}else{
float tmp = kMyConst1;
x = 2.f * tmp;
}
result[i] = x;
|
在处理器进行分支预测之后,处理器会首先并行执行值未真的那些ALU,再之后执行那些值为假的ALU,以达到并行处理的效果。
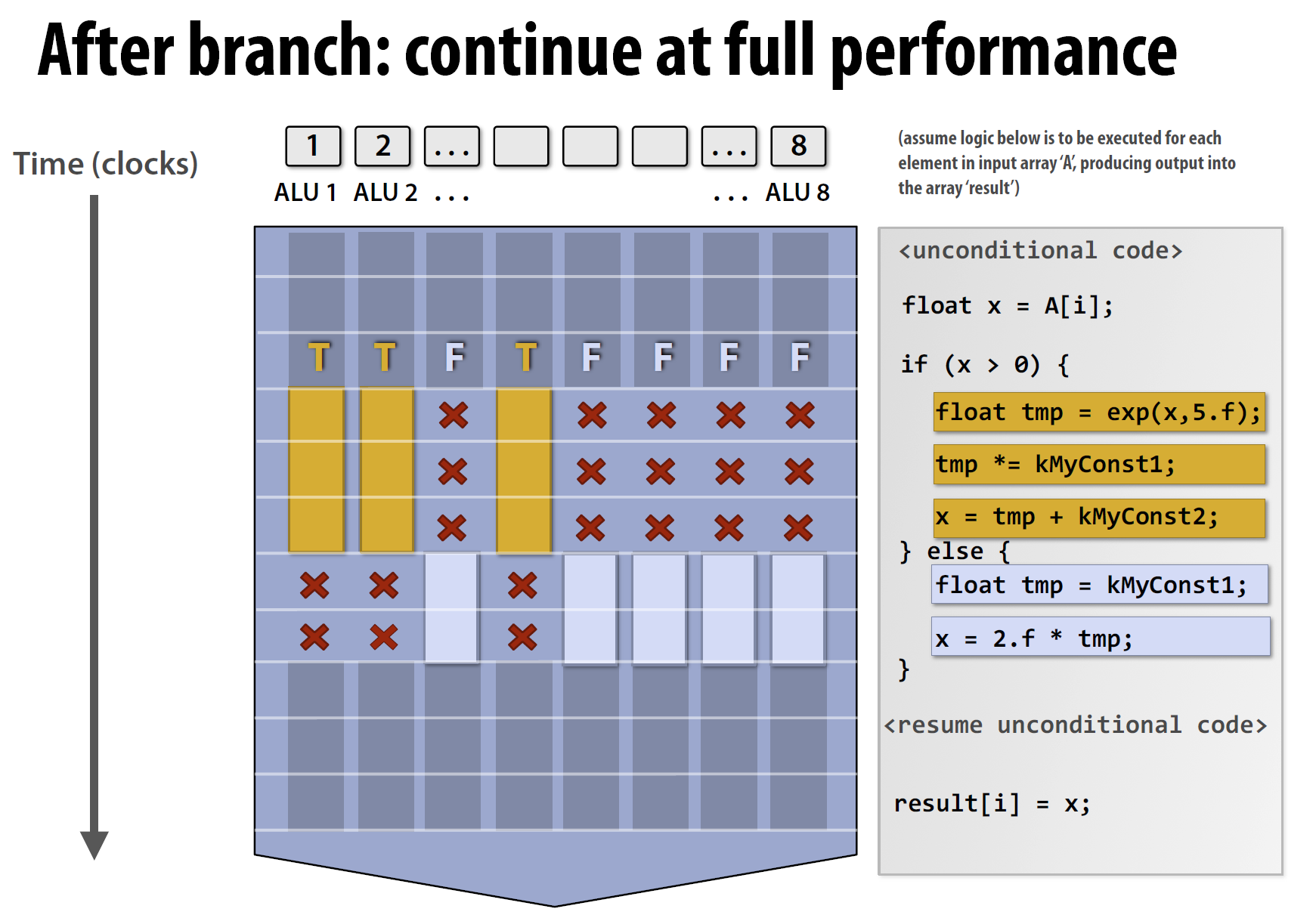
SMID的有关概念
- 要使用并行处理需要程序手动进行特定编码,比如使用:SSE、AVX等代码。
- 但是一旦使用并行处理,编译器无法检查与保证循环的独立性,需要自行保证
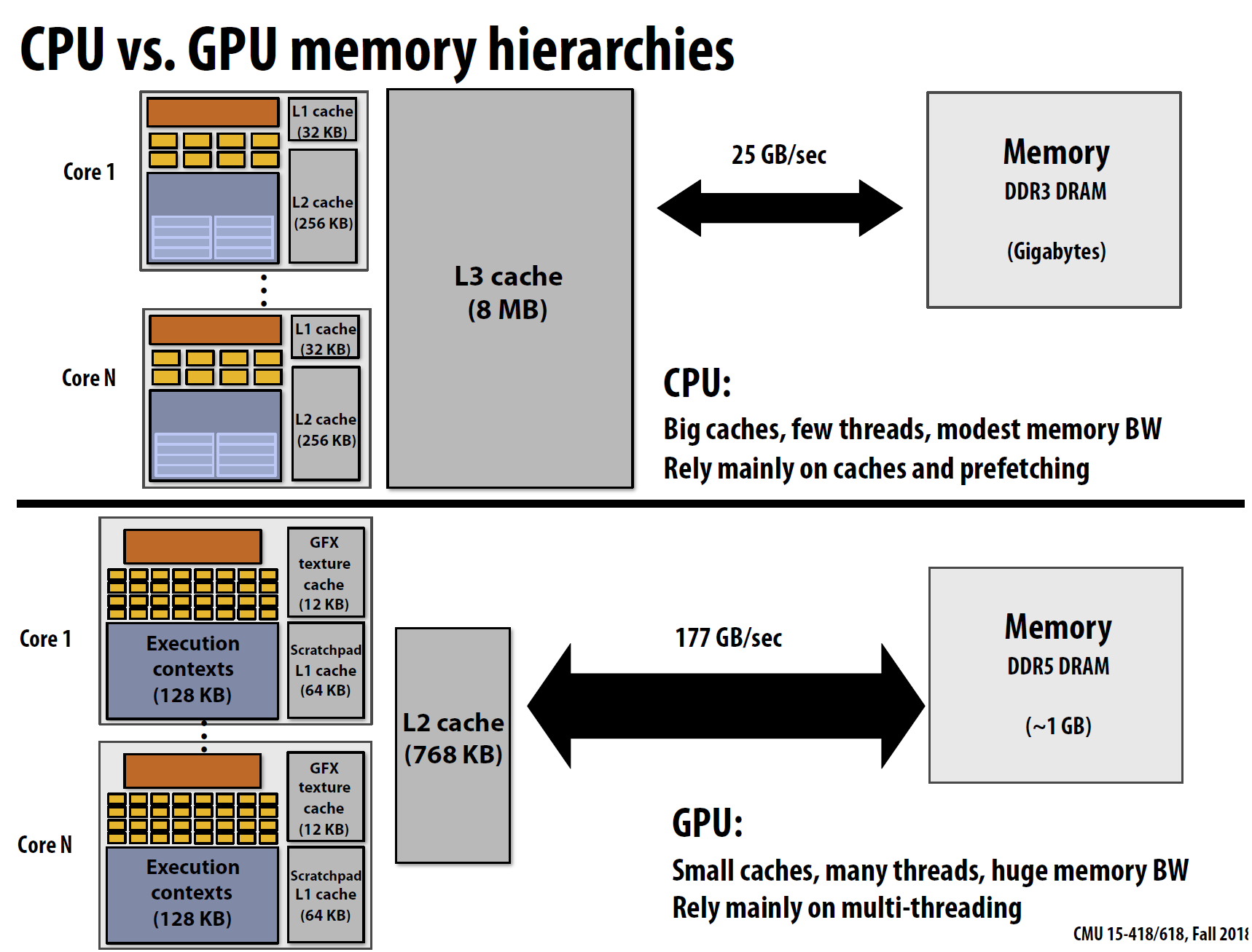
- GPU的数据并行处理性能要高于CPU的数据并行处理性能
比如:

Accessing Memory
术语
- 内存延时:内存延迟是指等待对系统内存中存储数据的访问完成时引起的延期。 单位:100机器周期、100毫秒
- 内存带宽:内存系统可以提供给处理器数据的速度。 单位:20GB/s
- 吞吐量(throughput):芯片单位时间处理数据的多少
现代处理器中不可避免因为内存延时而降低CPU处理速率,但是可以通过一些办法来“隐藏”内存延时,比如: